File Documentation
Jason M. Gleditsch 1
Sebastiano De Bona 2
Mathew R. Helmus 3
Jocelyn E. Behm 4
Last Updated: 07 April 2021
Source:vignettes/112_documentation.Rmd
112_documentation.RmdSummary
- Documentation files describe the data by stating their authors, methods, editing, and attributes
- The documentation files include Readme, Changelog, and Metadata files
File documentation tells anyone who wants to use the data, including yourself, what the data is and why, where, when, and for whom the data was collected. It will also let the user know how the data were processed. This is done through the inclusion of 3 separate text and/or CSV files. However, it is recommended that these files be text files so that they are easily distinguished from the CSV data files.
Readme File
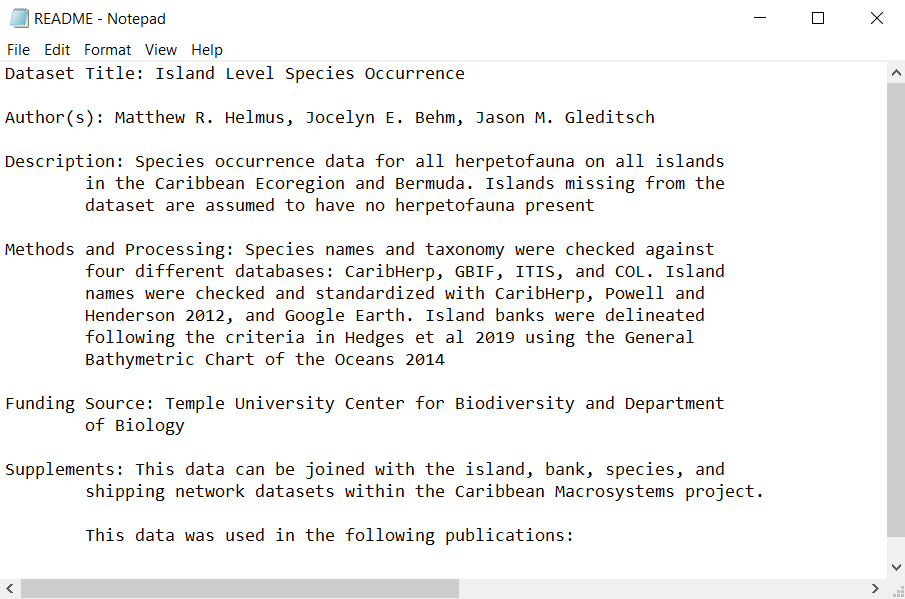
This file includes the title of the data set, the author(s) of the data, a short description of the data, any important methods used for data collection and processing, funding sources, and any other pertinent information. If your data does not include that many files and types, you only have to create one Readme file for all of the data. However, if you have many data files and/or your data consists of many types, you should make multiple Readme files for each data file (or type if you have a lot of file of the same type such as photographs). Below is an example of a Readme file for the Caribbean Macrosystems project:
Metadata File
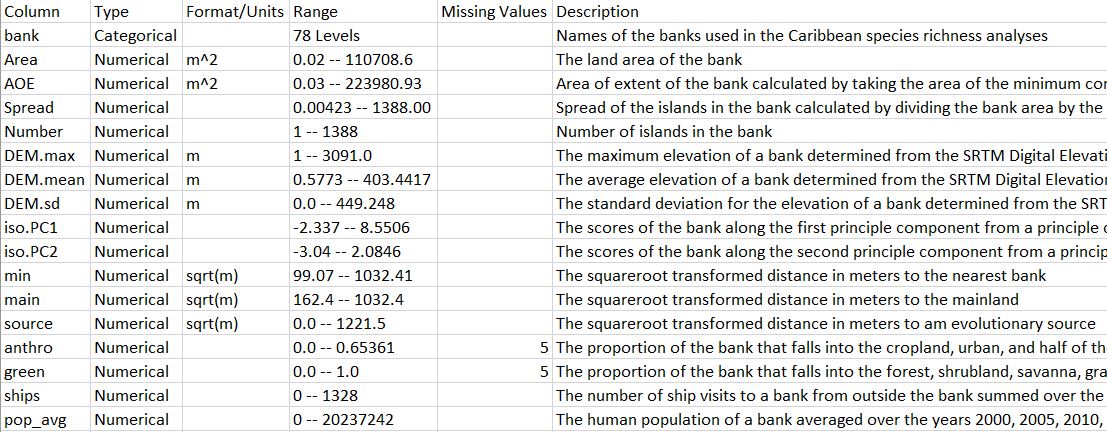
The file that describes the data, including data types, units of measure, factor levels, and a description of what the data represent. It is easiest to create metadata files as a CSV file then changing the file extension to .txt to make these files easily distinguished from the data files. We are currently working on a metadata() function in the iEcoDMP package to make the creation of these file easy (iEcoDMP is currently under construction). Below is an example of a metadata file for the bank data used in the Caribbean Macrosystems project:
Changelog File
A record of the changes you made to the data. They should be organized by version with each change made grouped by which version that change was made on. Changelogs can be made for entire projects, groups of data within a project, or single data files. In the case of entire projects and groups of data within a project, the changelog should be broken into sections for each data file name followed by each version of that file. Even if all of the changes and or edits to your data are made with R code, you should still have a changelog that at least provides the location of the data editing script and a brief description of what is done with that code. An example changelog for the Caribbean Macrosystem biodiversity data is below:
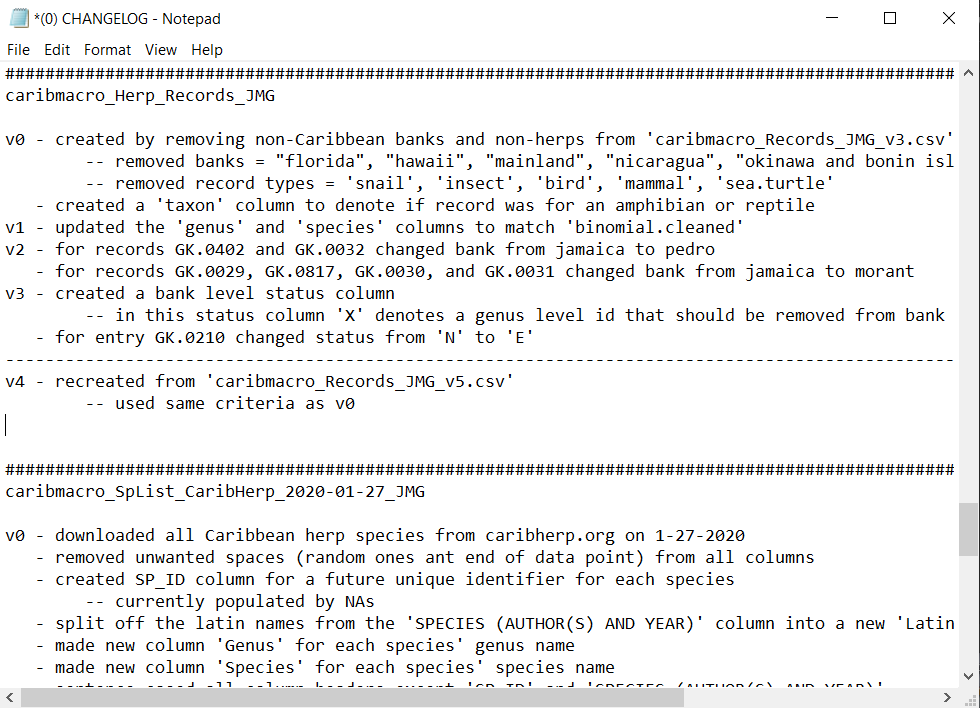
Note: that in this changelog there are multiple files with each file having its own section for each of its versions (for caribmacro_Herp_Records_JMG there are 4 versions).
Also, note that the file name for the Changelog starts with a “(0)” this is to make the changelog easy to find in a folder with multiple files in it. This can be done for all of the File Documentation files to make them easy to find.
File Documentation Naming and Storage
The documentation files should be kept in the data folder. It is up to you if they are kept with the data or within their own subfolder named ‘File Documentation’ that is in the root data folder. The naming conventions for these files are as follows (there should be ‘_’ between each part):
| Document Type | Naming Convention |
|---|---|
| Meta Data | \(<Data \space File \space Name>\_METADATA\) |
| Readme Files | \(<Project \space Name>\_(0)\_README\) |
| Project Changelog Files | \(<Project \space Name>\_(0)\_CHANGELOG\) |
| Individual Changelog Files | \(<Data \space File \space Name>\_CHANGELOG\) |
| Individual Readme Files | \(<Data \space File \space Name>\_README\) |
The ‘(0)’ is make those files easy to find since they will be at the beginning of the project group when the files are sorted by name.
Temple University, jmg5214@gmail.com↩︎
Temple University, sebastiano.debona@gmail.com↩︎
Temple University, mrhelmus@temple.edu↩︎
Temple University, jebehm@temple.edu↩︎